Dedicated vs. Shared Databases: A ‘MySQL has gone way’ fix
· 1058 wordsWhile working on a data heavy web application recently we noticed some strange unstable performance with our SQL database – this is a post about how we investigated it and what we did about it.
The application was written in PHP and hosted on Heroku in the EU region. We were using a ClearDB database, also hosted in the EU.
The Problem#
Occasionally we noticed our web application would have a performance spike for seemingly no reason at all causing Heroku to throw a H12 timeout error and an error message to our users. This would happen roughly once a week. Checking the logs, we could see that it was a problem connecting to our database, the exact message showing up was a ‘MySQL server has gone away’ – something we became familiar with over time.
Warning: PDO::__construct(): MySQL server has gone away ... on line 52As the problem continued we started saving these logs each time it happened and built up a folder of error logs with 8-10 instances of this problem.
What we tried and didn’t work#
1) PDO Attributes. To begin with we changed our database connection handler to include:
$pdo->setAttribute(\PDO::ATTR_TIMEOUT, 600); // 10 mins
$pdo->setAttribute(\PDO::ATTR_PERSISTENT, true);
The idea behind these changes was to extend the timeout for the database and enabling a persistent connection (although risky) we were hoping it would keep the connection open and use the same connection to the database (even though we’re using a singleton design pattern). At this point, we thought the problem might be because we were running out of connections.
2) Reconnect. The next step we took was to write some auto-reconnect code into our database access object. This means that if a PDOException is thrown (MySQL server gone way), we wait a second and try again.
// Pseudo code
public function connect($attempt = 0)
{
try {
// PDO Connect
}
catch (\PDOException $e) {
if ($attempt < $max) {
sleep(1);
$this->connect($attempt+1);
}
}
}
This didn’t work for a number of reasons. Firstly many of the PDO exceptions were happening when we executed statements and not when we formed our connection (we later wrapped our statements in similar code though to no avail). Secondly, the database wasn’t coming back quickly enough for this to have any effect, so it would try to connect a few times and fail each time – still causing a timeout.
3) Increasing Dynos. Using our backlog of error logs we had been saving, each time this problem occurred we realised it was between 9-10am and 12-1pm – our peak times. We tried increasing our Heroku dynos (server instances running the PHP code) between these times to help manage the problem but this had no effect – it might have even made it worse, with the possibility of more connections active at one time.
4) Contacting ClearDB. Our last resort was to file a support ticket to ClearDB to help us out with the problem. They kindly got back to us and we sent a few messages back and forth, the result being they told us we needed the optimize our queries. We did this and the problem continued and this solution didn’t sit right with us because under normal conditions our queries would run well under 1/2 a second.
Our Solution#
One crazy Wednesday morning, our application hit this problem nearly 50 times in the space of a couple of hours and with customers contacting us we needed to do something about it. At this point we realised our staging environment and other Heroku apps we’d built, also using a ClearDB database, were hitting the exact same problem, even though they were on different databases instances. This lead us to believe that it wasn’t a problem on our end after all.
We had been toying with the idea of trying a recently released Heroku addon called JawsDB which, although slightly more expensive, offered dedicated MySQL instances which would also match the web app’s Heroku location – so we could keep our data in Europe. The databases were not only held within the EU though, they were also held within the same data centre. This is because both Heroku and JawsDB are built on AWS.
Within the morning we had a migration script ready to go. Our simulation runs were a success. And with only a couple of minutes down-time we had completed a full migration and switched over to JawsDB.
… And the problem vanished. MySQL had gone way no more.
(Side note: if anyone knows of a better way to migrate an SQL database than a mysqldump and loading that file back into the mysql command – I’d love to know.)
A Comparison#
The move from ClearDB to JawsDB resulted in an increase to the performance of our app for a number of reasons:
JawsDB was a higher spec database (so far as I could tell), JawsDB – 66 connections, ClearDB – 15 connections, as just one example.
Performance increase could have resulted from the location of the database: being within the same data center likely resulted in a decreased latency between app and database (making an even bigger difference with non-persistent connections). With ClearDB using Azure, the latency for each query would have been that much higher.
The reason we are no longer seeing any ‘MySQL server gone away‘ messages, is likely to be that JawsDB is a dedicated database instance, so the number of connections to it is just what you’re using. With ClearDB however, even though you’re limited to 15 connections yourself if you check the number of connections to the database server with MySql Workbench it’s more like 200/300.
Here’s a comparison:
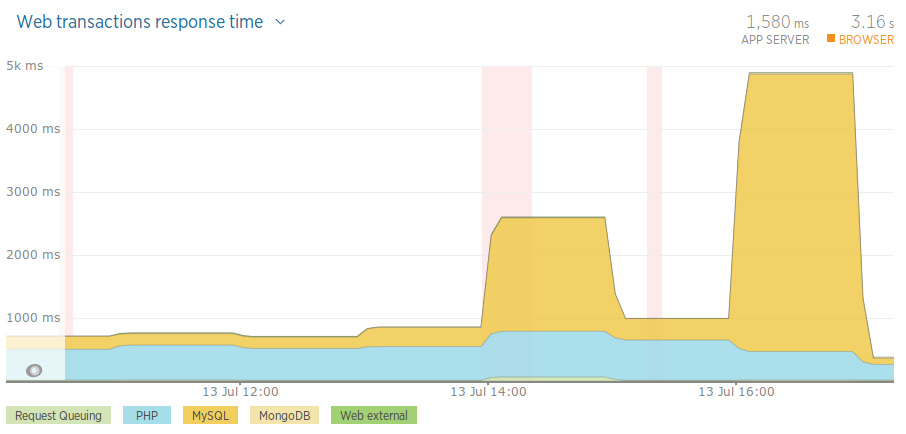
Before: – Monday
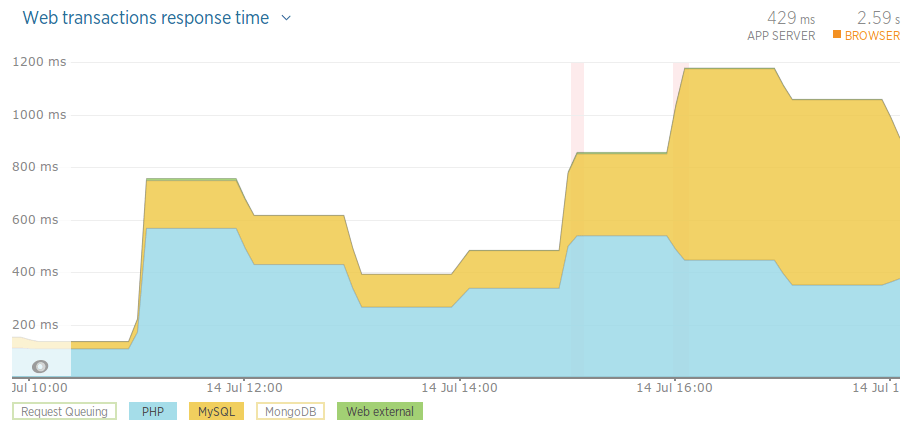
Before: – Tuesday
After: – Thursday
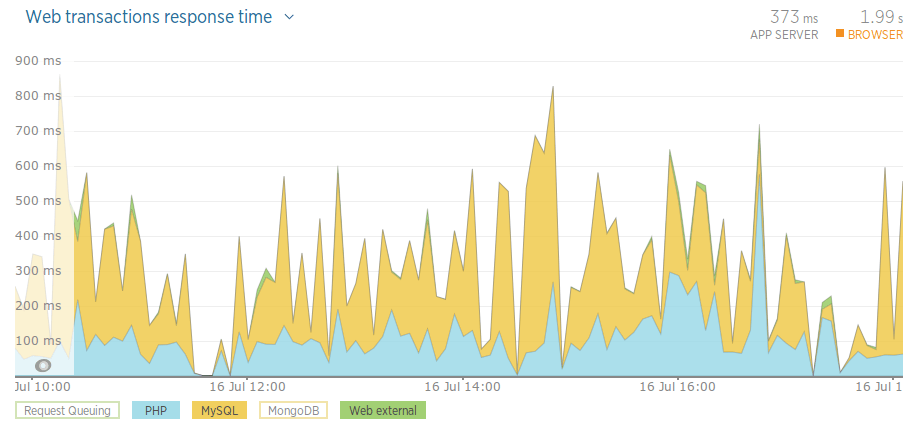
Please note: these aren’t particularly accurate results. We might have had more load on the Monday and Tuesday. The hours picked should be around 10am-6pm, but aren’t exact. We’re also relying on New Relic for these stats. Having said this, they give a good indication as to how our app is doing.
If you’ve encountered similar problems, we’d love to hear from you – post a comment or drop us an email.

About the Author: Edd Turtle
Edd is a PHP and Go developer, specialising in building scalable web applications. He enjoys blogging about his experiences, mostly about creating and coding new things he's working on and is a big beliver in open-source and Linux.